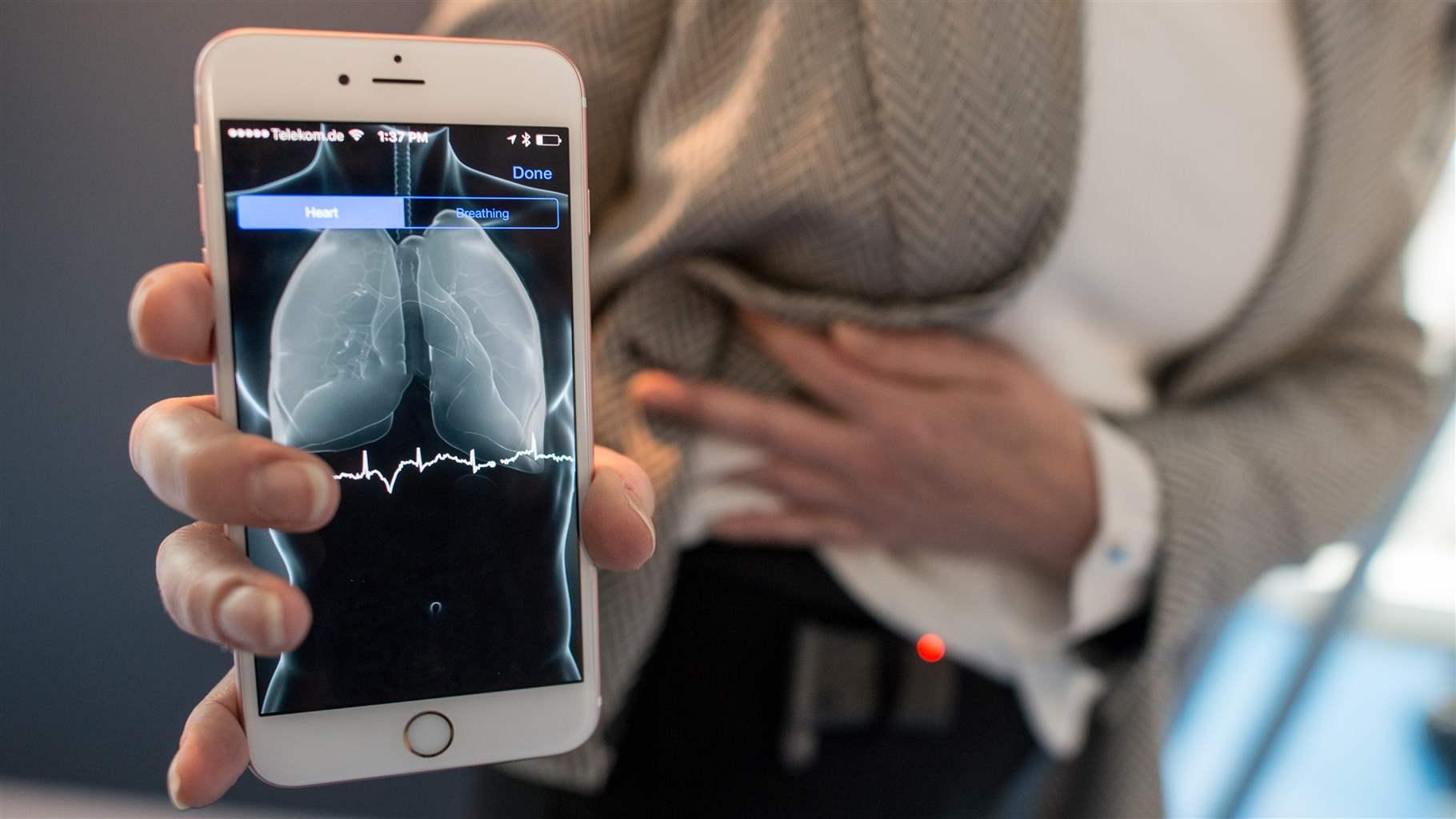
Following the record high of interests in biotech Q1 2021, it is turning out to be progressively challenging to tie down the subsidizing importance to put up a health tech item for sale to the public. With a 61% decrease in adventure financing in biotech as per Cove Extension Bio. Financial backers are trying to diminish the chance and time to profit from their ventures. Besides, it can frequently be fundamentally more testing to fund-raise preceding getting approval from controllers than subsequently. Administrative bodies characterize measures that advance capable turn of events and conveyance of protected and successful clinical gadgets. Meeting administrative achievements is in this way really difficult for gadget designers to meet to make business progress. Out and out, this features the significance of understanding what controllers are searching for and best practices for meeting their measures in an expense and time-compelling way. This article talks about a few vital characteristics of good datasets for creating computerized reasoning (simulated intelligence) and AI (ML) wellbeing innovation as well as ways to assess instruments. It can speed up improvement, approval, and administrative freedom for such advances.
Characteristics of a solid dataset
The FDA, MHRA, and Wellbeing Canada have mutually characterized 10 Great AI Practices (GMLP) that go about as direction for engineers of clinical gadgets that influence computer-based intelligence/ML innovation:
Predisposition in clinical man-made intelligence might arise when models need variety in quiet socioeconomics and sickness show. Engineers should dispassionately assess the exhibition of their innovation in the planned patient populace. Completely and precisely marked information can be unquestionably valuable to assess the representativeness of datasets for given patient populaces.
1. Multi-disciplinary skill is utilized all through the absolute item life cycle
2. Great computer programming and security rehearses are carried out
3. Clinical review members and informational collections are illustrative of the planned patient populace
4. Preparing informational indexes is autonomous of test sets
5. Chosen reference datasets depend on most ideal that anyone could hope to find techniques
6. The model plan is custom-made to the accessible information and mirrors the expected utilization of the gadget
7. Zero in is put on the exhibition of the human-artificial intelligence group
8. Testing shows gadget execution during clinically applicable circumstances
9. Clients are given clear, fundamental data
10. Sent models are checked for execution and yet again preparing gambles are made due
Specifically, the rules numbered 3, 4, and 5 characterize attributes of top-notch datasets utilized for preparing and approval of simulated intelligence/ML models.
Optimizing artificial intelligence/ML gadget advancement and administrative leeway with admittance to on-request, quality information
Luckily for pioneers in the wellbeing tech space, there is an undeniably more prominent amount and nature of choices accessible to acquire close prompt admittance to organized information readily available. The following are a few courses to get information:
Clinical review with information sharing arrangement:
This is the conventional course of producing information. Be that as it may, this approach presents difficulties – there is ordinarily a huge lead time including concentrating on plan and patient enlistment. It can be exorbitant. The variety of the patient populace is in many cases directed by the area and number of locales where information is gathered, in this manner some clinical predispositions might be brought into models prepared with the information gathered in the clinical review.
United learning:
As opposed to preparing a model utilizing a unified informational collection, combined learning happens when engineers share their models with different establishments that then train the model with their separate informational collections. The outcome is a model prepared on a different exhibit of information, without the touchy information truly leaving the organizations’ servers
Engineered information. This approach is acquiring fame as it very well may be somewhat cheap and quick to create enormous datasets from a more modest subset of genuine information. Notwithstanding, engineers ought to be careful that blunders might be presented by manufactured information.
Information accomplices:
Information accomplices assume the undertaking of obtaining, de-recognizing, and marking information with the goal that engineers don’t need to. Regularly, by working with information accomplices, engineers can promptly get to enormous informational indexes. Staying away from the dangers related to taking care of patient data as the information will as of now be de-distinguished.
Healthtech pioneers might wish to search for the accompanying characteristics in informational indexes:
1. Dependably obtained
2. Accessible, to effectively recover and sort information in view of explicit rules
3. De-distinguished to limit the gamble of HIPAA infringement
4. Empowers adaptable information naming
5. Worked in view of FDA and WHO system consistency
There is an enormous chance to advance medical services in huge amounts at a time by utilizing man-made brainpower and AI. Information delegates and accomplices can help pioneers of clinical innovation to all the more effectively beat boundaries to getting to a lot of different information that might have recently addressed almost unfavorable hindrances for little, lightweight new businesses to survive.